- Background
- Graph Formulation
- Experiment
- Conclusion
- Future Improvements
- Appendix: Low-Frequency Stock-Picking Procedure Breakdown
- Acknowledgement
- Reference
Background
Stocks are classified into different sectors (Energy, Finance, Health Care, etc), and stocks within the same sectors are assumed to have similar behaviors (movement patterns and risk profiles). Fund managers worldwide demand a precise classification to control portfolio sector exposures and thus minimize risks brought by some specific sectors. This could be considered a sector-level diversification.
The most widely used industry classifications are China CITIC (中信) and SWS Research (申万宏源) for China A-share. They provide a professional guideline for a long-term stock industry classification. However, the classification is fixed and fails to capture short-term correlations between stocks in different sectors, and thus fails to embody short-term co-movement risks between conventionally unrelated stocks. This particular risk could hardly be hedged against if the fund manager use a fixed industry classification scheme.
Therefore, a dynamic industry classification is recommended for institutional traders, especially hedge fund portfolio managers on low-frequency trading strategies (change stock holdings each day, for instance).
In this project, we leverage the benefits of graph-based analysis to improve the final stage of low-frequency stock picking strategy research – Markowitz Portfolio Optimization – by replacing the static industry exposure constraint with a dynamic one, trained on historical return series. In other words, we are “optimizing an optimization”.
For readers unfamiliar with the low-frequency quant research pipeline, the appendix could be helpful for your convenience.
Graph Formulation
To create a dynamic stock classification from market data, we believe that graph techniques may help filter information and naturally represent industry information in their dense graph embeddings. In a nutshell, two stocks are connected if they demonstrate a strong correlation over the given observation time period, and by that connectivity we may partition the graph and obtain communities.
Build Graph from Financial Data
We would like to build a graph whose nodes are stocks and edges are indicators of connectivity. Suppose there are $N$ tradable assets and $T$ days for observation, we take the time-series correlation among stocks as a criteria to add edges[1].
To compute the time-series correlation, suppose $s_{i,t}$ is the (close) price of asset $i$ at time $t \in {1, …, T}$, then the daily return is $r_{i, t} = \frac{s_{i, t} - s_{i, t - 1}}{s_{i, t - 1}}$ ($t$ starts from 2, which means there are only $T - 1$ returns). Then for any $i, j$, the time-series correlation is thus given by
\[\rho_{ij} = \frac{\sum_{t=2}^T (r_{i, t} - \bar{r}_i)(r_{j, t} - \bar{r}_j) }{\sqrt{[\sum_{t=2}^T (r_{i, t} - \bar{r}_i)^2] [\sum_{t=2}^T (r_{j, t} - \bar{r}_j)^2]}}\]where \(\bar{r}_i = \frac{r_{i,2} +r_{i,3} + ... + r_{i, T}}{T - 1}\). This could be considered as the “weight” of the edge between stock $ i $ and stock $ j $. One sometimes need to convert weights to distance between two nodes, and a naive form is give by
\[d_{ij} = \sqrt{2 (1 - \rho_{ij})}\]Given the similarity measures (correlation) and distance measures, we may build graphs by using the following methods:
- Asset Graph (AG)[3]: connect if $ |\rho_{ij}| $ is beyond a pre-defined threshold. Asset graph encapsulate global structure well but fails to capture local ones.
- Minimum Spanning Tree (MST)[8][9]: sort all $\rho_{ij}$ in a descending order, add the edge if after addition the graph is still a forest or a tree (Kruskal’s Algorithm). MST matches the understanding of investors on the market, where risk propagate from a central node to others[6], but is well-known to be unstable across time.
- Planar Maximally Filter Graph (PMFG)[2][4][5]: simiilar to MST, but add edge if after addition the graph is still planar. This adds more stability to MST, but may be a little harder to train.
In addition, Random Matrix Theory (RMT)[3][7] selects information from the correlation matrix and feed back to the previous three models as a refinement.
In this project we use all four types in our experiment.
Community Detection from Constructed Graphs
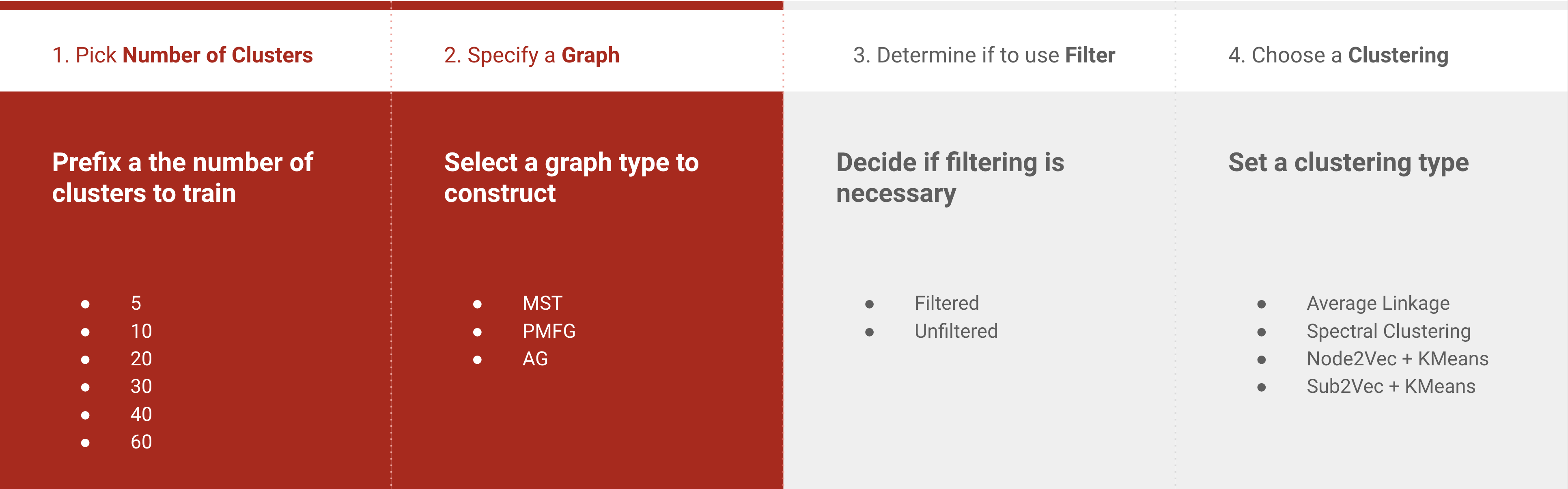
To control the number of industry, we pick algorithms that help generate a prescribed number of clusters. The following are implemented:
- Spectral Clustering
- Average Linkage Clustering
- Node2Vec[10] + KMeans: KMeans on Node2Vec embeddings;
- Sub2Vec[11] + KMeans: KMeans on Sub2Vec embeddings.
Graph Evaluation
To evaluate if the re-constructed classification is “good”, we go through the entire low-frequency stock picking pipeline and plug in new industry information in the final step – Markowitz Portfolio Optimization – to see if there is a performance gain in our strategy.
We focus on the following four metrics to measure performance:
- Excess Return: the excess return of the strategy with respect to the index / market;
- Max Drawdown: max decrease of the portfolio in value;
- Turnover: measure the rate of invested stocks being replaced by new ones;
- AlphaSharpeRatio: return / volatility, measure the ability of maximizing returns over risk.
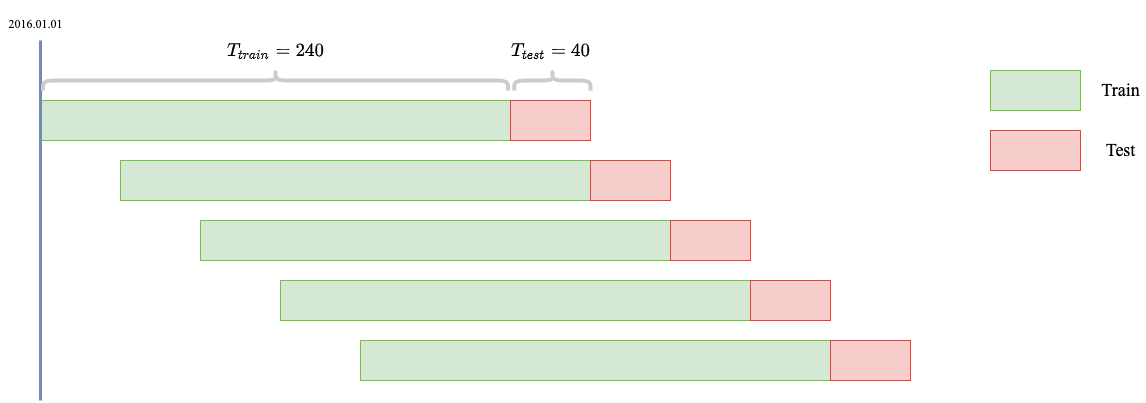
The dynamic property is done by a rolling-based train test schemed outlined as follows: we train the graph using $T_{train} = 240$ days and test the performance of the graph in the following $T_{test} = 40$ days. Then we move forward $T_{test}$ days to retrain the graph. Note that the test periods are not overlapping, and the train test periods are the same in the factor combination (machine learning) part of the low-frequency stock picking paradigm. We look at the metrics of the successive testing periods in our portfolio.
Experiment
Data
Provided by Shanghai Probability Quantitative Investment, this is a dataset of day-level A-share stock information.
In this project, we will focus on a particular stock pool named zz1000 (中证1000) favored by many investors. This is a pool of 1000 mid-size market cap stocks, and the pool replace stocks every 6 months. The following stats on zz1000 is taking the union of all stocks appeared in this pool in history.
| stock_pool | start_date | end_date | num_stocks | num_industry | num_features | avg_nan_rate | avg_FloatMarketValue |
|---|---|---|---|---|---|---|---|
| All | 20150101 | 20211231 | 4752 | 28 | 24 | 0.215112 | 1.363993e+10 |
| ZZ1000 | 20150101 | 20211231 | 1847 | 28 | 24 | 0.121805 | 6.898919e+09 |
We also list the 24 features available to compute alphafactors (for gathering excess returns) and risk factors (for controlling porfolio risks). The meaning of these names is self-explanatory.
| Price | Volume | Status | Others |
|---|---|---|---|
| AdjFactor | TurnoverRate | TradeStatus | Total Equity |
| PreClosePrice | TradeVolume | IssueStatus | |
| OpenPrice | TradeValue | STStatus | |
| ClosePrice | FloatMarketValue | SuspendStatus | |
| DownLimitPrice | FloatShare | UpDownLimitStatus | |
| UpLimitPrice | TotalMarketValue | ||
| HighestPrice | |||
| LowestPrice | |||
| Price | |||
| VWAP | |||
| TrueRange | |||
| RangeRate |
Experiment Details
Using LightGBM to combine 646 alphafactors based on the above features, we trained a machine learning model predicting stock daily returns. With prediction fixed, we use portfolio optimization with trained dynamic industry exposures as constraints instead (see appendix for more details). The following set of rules apply for all backtests:
- Commissions deducted (0.15%)
- No latency/slippage (immediate order execution)
- No trading on stocks issued in their first 60 trading days or stocks hitting up limit or down limit
- Change stock weights on a daily basis
- Trade at open (open to open return)
- Trade on member stock of zz1000 and use zz1000 as the benchmark for excess return (index enhancement style)
- Select top $M = 100$ stocks on each cross-section to invest (long group)
Performance Results
This gives the following evaluations:
Stock Pool: zz1000 member stocks
Benchmark: zz1000 index
Time Period: 20170701 - 20211231
| Model | AlphaReturn (cumsum) | AlphaSharpe | AlphaDrawdown | Turnover |
|---|---|---|---|---|
| LgbmRegressor | 145.64 | 3.65 | -11.58 | 1.21 |
| LgbmRegressor-opt | 146.73 | 2.96 | -29.79 | 1.11 |
| .. | .. | .. | .. | .. |
| 40-cluster PMFG Unfiltered Spectral | 154.45 | 3.15 | -22.69 | 1.11 |
| 10-cluster PMFG Filtered Average Linkage | 160.95 | 3.32 | -26.77 | 1.11 |
| 30-cluster AG Unfiltered Sub2Vec | 160.96 | 3.24 | -23.05 | 1.10 |
| 5-cluster MST Unfiltered Sub2Vec | 163.26 | 3.27 | -27.39 | 1.11 |
| 20-cluster PMFG Filtered Node2Vec | 164.68 | 3.30 | -27.06 | 1.11 |
Compared to the original optimization result, we observe a 12.23% improvement in excess return and 12.16% improvement in excess Sharpe ratio.
Since factors based on price and volume are known to have lost their predictive power staring from 20200701, we also look at the performances when they still were still helpful for prediction.
Stock Pool: zz1000 member stocks
Benchmark: zz1000 index
Time Period: 20170701 - 20200701
| Model | AlphaReturn (cumsum) | AlphaSharpe | AlphaDrawdown | Turnover |
|---|---|---|---|---|
| LgbmRegressor | 150.64 | 6.06 | -4.59 | 1.23 |
| LgbmRegressor-opt | 170.31 | 5.43 | -6.76 | 1.12 |
| .. | .. | .. | .. | .. |
| 10-cluster PMFG Filtered Sub2Vec | 173.10 | 5.49 | -5.51 | 1.12 |
| 5-cluster MST Filtered Sub2Vec | 182.89 | 5.78 | -7.14 | 1.12 |
| 10-cluster AG Filtered Sub2Vec | 181.50 | 5.64 | -7.40 | 1.12 |
| 20-cluster PMFG Filtered Node2Vec | 184.21 | 5.85 | -6.42 | 1.12 |
In this period, we observe a 8.16% improvement in excess return and a 7.73% improvement in excess Sharpe ratio, compared to the original optimization result.
In both time periods, filtered PMFG yielding 20 clusters using Node2Vec gives the best result in overall excess return.
Although improvements are observed in overall excess return, none of the “optimized” result beats the original prediction in Sharpe Ratio or drawdown control. That is, the optimizer sacrifices return per unit risk (Sharpe) to achieve higher overall excess return, and this is likely due to a strict constraint in turnover rate. It is empirically, however, possible for Markowitz portfolio optimization to improve both Sharpe ratio and excess return. More data, in-particular higher-frequency ones, are required to supply a better prediction with lower turnover rate to start with so that turnover constraint can be satisfied without sacrificing much of Sharpe ratio.
For a complete list of results, check out summary_20170701_20211231.csv and summary_20170701_20200701.csv available on github.
Performance Breakdown
We examine the results in detail and observe the following:
- Exceptional performance gains are not due to randomness
- Filtering helps improve Sharpe Ratio
- Demonstrate a potential for further improvements in theory by the efficient frontier
Improvements Are Not Due to Randomness
Since all optimization are based on the same prediction (for each day, the set of stocks invested are the same across different optimization results), we simulate weights for the selected $M = 100$ stock each day using technique introduced by Fan et al. (2016)[13]. To uniformly generate positive weights $\xi_i: \sum_{i=1}^M \xi_i = 1$, one may generate i.i.d. $X_i \sim Exp(1)$ and set $\xi_i = X_i / \sum_{i=1}^M X_i$.
In the following plot, grey lines are simulated PnL curves, black line is the original optimized one, and others are curves using dynamic industry. None of the 1000 simulated curves supersedes optimized ones, which concludes that the optimized results are not due to random.

Moreover, we notice that the majority of optimization using a dynamic ones beat the original optimization, particularly before 20200701, starting from which the PnL curve no longer grows due to ineffective factors, affirming at least empirically that using a dynamic industry classification does help improve the optimization.
Filtering On Average Performs Better than Unfiltered Ones
The following robustness checks are six violin plots examining if filtering helps improve Sharpe ratio. From top to bottom, we split the trained industry by number of clusters, clustering type, and graph type respectively. The left column is the full period (20170701 - 20211231) and the right column is the truncated one (20170701 - 20200701). Within each of the plot, the left portion of each violin is the unfiltered performance and the right is the filtered counterparts.
 |
 |
 |
 |
 |
 |
We also see that there is little difference between different number of clusters prescribed, but that average linkage performs better than node2vec and sub2vec on average, and that MST and PMFG perform better than AG on average.
Further Improvement in Theory
To gauge the efficiency of mining returns per unit of risk, we may plot excess returns against realized risk. Here we use the max drawdown as a proxy for risk. The more it appear towards the top left (large return, small risk), the better it is, since it could gather more returns per unit of risk.
Ideally, as risk increases, more returns are expected, since returns are (arguably) the compensations for risks. However, we observe a undesired downward trend in the best fit lines for respective type of graphs during both the full period and the truncated one.
For comparison, here is the efficient frontier in theory.
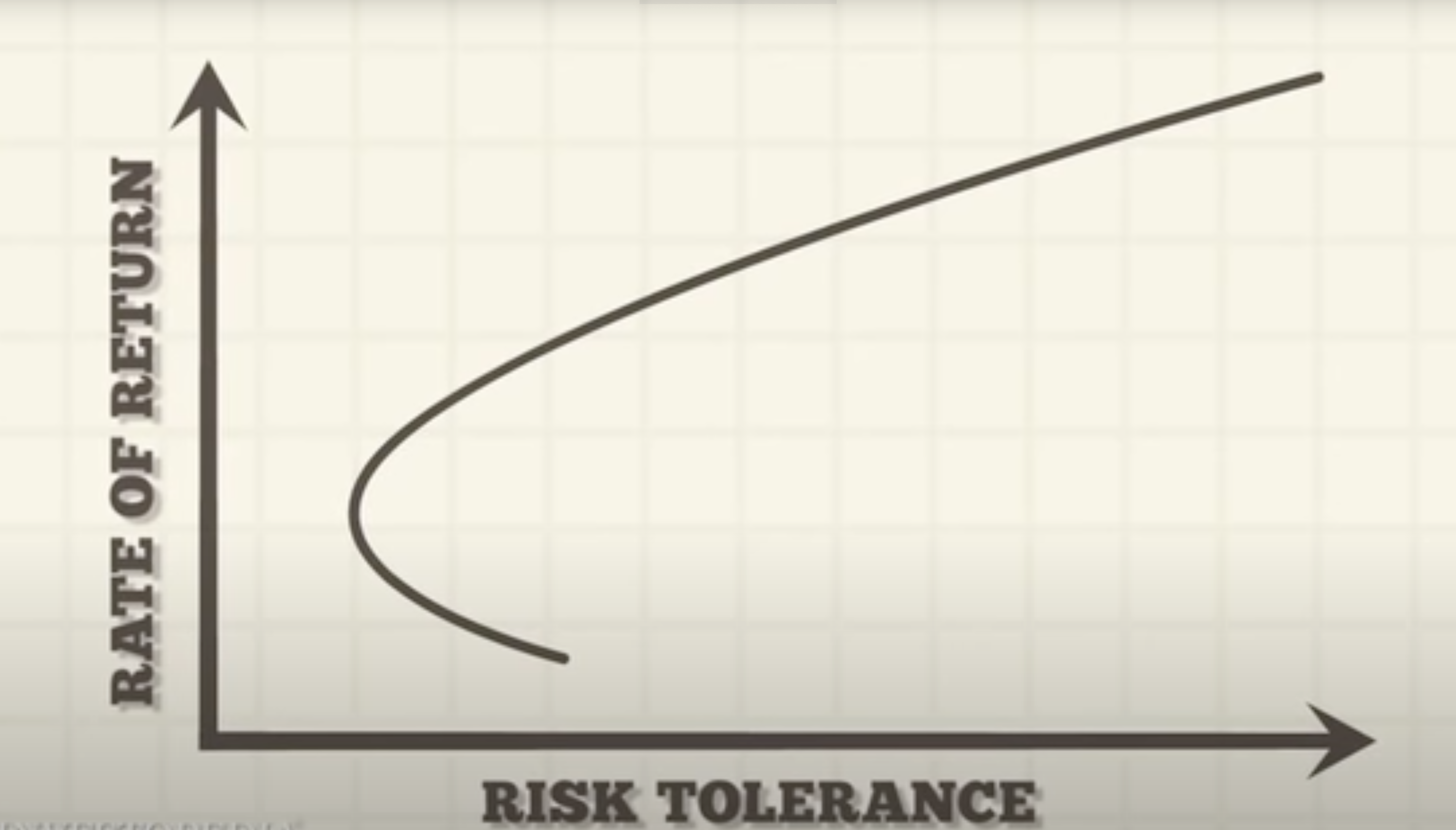
The exhibited downward trends show that our optimized results may not be hitting the efficient frontier. The way to reach the frontier is subject to further investigations.
Notice that the best fit lines reaffirm the rough equivalence between MST and PMFG, and that they are better than AG, matching the conclusion above.
Interpretability
One way to explain results is by looking at the distribution of proportion of trained industry. Some trained industry classification is more uniform than the other. That is, some deviate less from a uniform distribution where the number of stocks in different industry is the same. For instance, if we need 5 industries, and have two proportions of industries:
- example 1: [0.2, 0.21, 0.19, 0.19, 0.21]
- example 2: [0.4, 0.1, 0.3, 0.3, 0.1]
then example 2 is more unbalanced than example 1.
Since portfolio optimization, by design, imposes a uniform limit on the industry exposure, equal weights across stocks become less feasible. The optimized results may lean more towards some specific industries, thus in short-term getting higher returns and more risks simultaneously by exposing itself to those industries. So in general, the more unbalanced, up to a certain limit, a classification is, the more likely it would obtain higher return. Also, one classification could not be trivially too unbalanced, since this fails the purpose of sector level diversification and expose oneself too much to specific stocks.
To summarize, higher return could be obtained by training a more unbalanced industry classification, but only up to a certain point. After that threshold, the risk of overinvesting particular stocks surpass its benefit and would decrease overall returns.
The following verification by and large confirms our hypothesis.
Positive Relationship Between Unbalancedness and Performance
We measure the unbalancedness by calculating the total variation distance (TVD) between a trained industry proportion distribution and a uniform one. For instance, example 2 above gives a TVD of $(0.4 - 0.2)^2 + (0.1 - 0.2)^2 + (0.3 - 0.2)^2 + (0.3 - 0.2)^2 + (0.1 - 0.2)^2 = 0.08$.
A regression of excess return Sharpe Ratio against the log-scaled TVD yields a positive, albeit weak (p-value = 0.074 for the slope), correlation, confirming the general trend of obtaining more returns by having a more unbalanced industry classification.
(Note: the positive correlation becomes insignificant for the truncated time period, from 20170101 to 20200701, whose p-value is 0.147. And if split by filtered type, the correlation is likewise insignificant. For filtered part, p-value is 0.14, and for unfiltered portion, p-value is 0.315)
There is also a strong correlation (p-value = 0.000 for slope) between the unbalancedness and the turnover of the portfolio, as expected, for both the full period and truncated period: leaning more towards specific industries/stocks brings a larger change in weights of stocks across days, compared to a close-to-uniform weight distribution.

From these results, one may conclude that the increased turnover in this case adds more to return than to costs, since towards the right end, the Sharpe ratio is higher than the left.
But as noted above, too unbalanced a result brings more harm than good. The sweet spot is observed to be around the unbalancedness of the static industry classification (log(TVD) = -4.33). Partitioning the dataset into the part that is less unbalanced than the static classification and the part that is more unbalanced than it, we observe a significant positive correlation for the lesser part, and trivial correlation for the greater part, for both the full period and truncated period.

This again confirms our hypothesis where the positive correlation is valid only up to a certain threshold. It remains to show that the theoretical sweet spot is precisely or around the magnitude of deviation from uniform of th static classification.
The reason that static classification serves as an empirical threshold is likely that static classification is already a “good” classification of industry, thus rendering classification more unbalanced than that too biased and risky.
Moreover, we may draw a finding that to have high Sharpe ratio, one would like to train the industry to have roughly the same level of unbalancedness as the static classification one. More details to be discussed in the following section.
Unbalancedness by Choice of Parameters
The following kernel density plots by filter type, graph type, and clustering type show that unbalancedness could be use to distinguish among different choice of parameters. Viewing unbalancedness in each dimension, with the perception that higher Sharpe ratio could be obtain by getting more unbalanced classification, only up to a certain point, many of the observations derived in the result part could be explained.
By filter type, the peek of the filtered version is around the static one, matching our previous observation where filtered classification performs better than unfiltered counterparts on average.

By graph type, we see that both MST and PMFG has a peek around that static one, which coincides with the previous conclusion where MST and PMFG performs better than AG. The fact that AG only consider global connections/correlations without local ones, making it harder to discover local cliques, is also reflected by the balancedness of its output classification, which shows that AG is more balanced in industry proportion distribution than others.
By clustering type, average linkage is much more unbalanced than sub2vec ones, for instance, which also matches the conclusion above that average linkage performs better than sub2vec. Notice, in particular, that though sub2vec and node2vec share the same procedure (use deep learning to obtain graph embeddings and then go through KMeans), the respective unbalancedness differ vastly.
A Closer Look at Graph Embeddings
For sub2vec and node2vec, we may visualize the graph embeddings to see if clustering leans towards an unbalanced one or to the other direction.
The following are two embeddings generated by the same graph (20-cluster PMFG Filtered, on the return series of zz1000 member stocks in 20210101 - 20211231). We observe that node2vec in this case is much more unbalanced than sub2vec.
 |
 |
The reason for node2vec to have more local gathering is due to the biased random walk by design supported by node2vec. Sub2Vec, in the context of community detection, uses 2-hop neighbors as subgraphs for each node, which may have taken in insufficient amount of information to demarcate boundaries for stocks that have similar structure but are far apart from each other on graph. More investigation is required, including parameter tunning for each model to draw clearer boundaries as well as further optimize results.
Conclusion
Using a dynamic industrial classification to replace the static industry constraint in the Markowitz portfolio optimization process empirically boosts strategy performance. We implemented a dynamic industry classification training pipeline, accepting the number of clusters, the type of graphs (MST, PMFG, AG), the type of filter (filtered, unfiltered), and the type of clusterings (average linkage, spectral, node2vec, sub2vec) as parameters, and observe that on average filtered version is better than unfiltered ones and MST and PMFG are better than AG. We also conducted a simulation to demonstrate that the improvements are not due to random, and show in theory there is room for further improvement invoking the theory of efficient boundary. Lastly, we discovered that the unbalancedness of trained industry classification has a say in the final performance, where performance could be increased by training a more unbalanced classification but up to a certain threshold. The findings help explain most of our observations derived above.
Future Improvements
Due to limited data and computing resources, many ideas could hardly be materialized. Readers may continue improving the results by going along the following tracks:
- Incorporate features into graphs: both node2vec and sub2vec are agnostic of the underlying node features. Stocks have many features. A GCN-style of feature aggregation to train embeddings may be helpful, but whether it has information add-on by incorporating alpha factors / risk factors is subject to mathematical investigation. (Note: [6] provides a non-exhaustive proof of that there is no correlation between portfolio optimization and using a graph structure agnostic of node features to pick stocks. It may serve as a good starting point to back theory in using GCN)
- Replicate results after 20200701 using high-frequency data/feature/factor: current factors are not working after that. If more factors are added in, performance in the recent two years may or may not yield a different result.
- Examine trained industry’s connection with real industry: see if stocks in cluster one has a common trait and cluster two has another for more interpretability.
Appendix: Low-Frequency Stock-Picking Procedure Breakdown
In low-frequency quantitative investment research, the central goal is to predict future daily returns as accurate as possible. There are the following four steps[12]:
- Mine Factors: perform feature engineering on stock information to facilitate predicting future returns;
- Combine Factors: use machine learning algorithms to combine mined factors to predict future return;
- Portfolio Sort/Backtest: at each day, given the prediction, pick the top $M$ number of stocks with the highest returns from all tradable stocks ($M$ depends on the stock pool, in this project $M = 100$). Mimic this using the history data to test if the predictions are accurate;
- Portfolio Optimization: given the selected stocks, assign appropriate weights to each one to control the overall risk exposure (Industry Exposure, for instance).
In this project, we would like to use graph-based analysis to re-classify stocks and see if a dynamic industry classification could help improve portfolio optimization performance. The performance is measured by overall returns and realized volatility given a tested timeframe.
Mine Factors
Starting from 1960s, people started to use factor model to predict stock returns. CAPM (Capital Asset Pricing Model) was one of the first formal attempts. Suppose we have $N$ tradable assets, the simplified form is written below:
\[\mathbb{E}(R_i^e) = \alpha_i + \beta_i \lambda_{market}, \; \forall i \in \{1, ..., N\}\]where $\mathbb{E}(R_i^e)$ is the predicted future return of asset $i$ and $\lambda_{market} = \mathbb{E}(R_m)$ is a factor and is the current market return. That is, future stock return depends on current market return. A simple linear regression could help us identify the exact values of the coefficients for each asset $i$.
In 1993, FF3 (Fama-French Three-Factor Model) was proposed and its author later won the Nobel Prize in Economic Sciences. It builds on CAPM and appended two other factors: market capitalization and book-to-market (BM) ratio.
\[\mathbb{E}(R_i^e) = \alpha_i + \beta_{i, market} \lambda_{market} + \beta_{i, cap} \lambda_{cap} + \beta_{i, bm} \lambda_{bm}, \; \forall i \in \{1, ..., N\}\]One could observe that there is nothing stopping us from adding more factors (more features typically brings lower MSE in regression tasks, although collinearity needs to be either eliminated or circumvented by picking an ML model that is robust to collinearity). Many modern quant practitioner focus on mining factors. Suppose we have $K$ factors, then our model becomes
\[\mathbb{E}(R_i^e) = \alpha_i + \sum_{k=1}^K \beta_{i, k} \lambda_{k} = \alpha_i + \mathbb{\beta}_i^T \mathbb{\lambda}, \; \forall i \in \{1, ..., N\}\]where $\mathbb{\beta}_i, \mathbb{\lambda} \in \mathbb{R}^K$.
In a hedge fund, usually $K > 2000$. But for limited data and computing resources, in this project $K = 646$. These includes factors computed from daily price and volume data (momentum, reversal, idiosyncratic returns, technical indicators, and other confidential ones).
Combine Factors
With the model above, we would like to obtain the trained values for \(\mathbb{\beta}_i\) to predict future stock returns. Suppose we have $ N $ assets, $ K $ factors, and pick $ T $ days to be our training period ($T_{train} = 240$ in this project. This is roughly a year since there are only 245 trading days per year), the $ X $, features, and $ y $, prediction goal, are constructed in the following way: we flatten each factors and vertically concat them with correct dates aligned, and then do the same thing for the return panel data. Features in different dates in the same training period are equally weighted, though it is known empirically that an exponential decay on dates could boost performance.
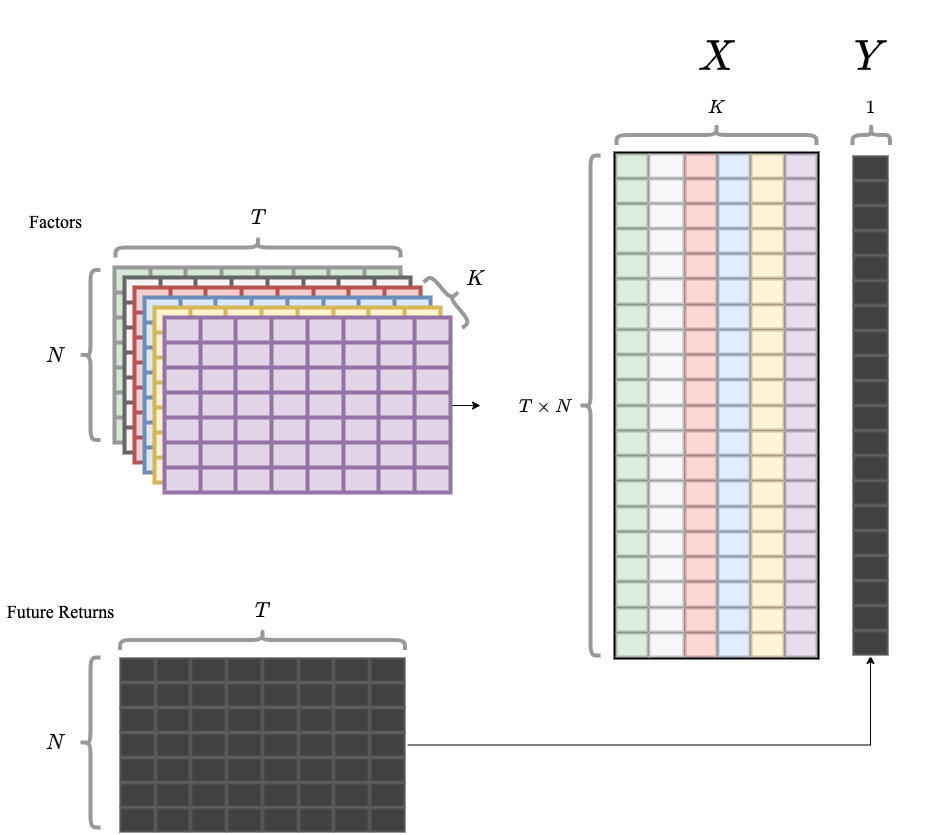
For scalibility, we focus on LightGBM regressor. LinearRegressor is also included for performance comparison.
Portfolio Sort / Backtest
With the trained model, we could now predict the returns for all tradable stocks tomorrow. Pick the top $M$ stocks ($M = 100$ in this project, and essentially this is picking one-tenth of the stocks from the pool of zz1000). $M$ should not be too small since our prediction may be wrong, capturing stocks not with the hightest returns; nor could $M$ be too large, since we may not have enough money to invest in all of them (there is a minimum purchase requirement per stock).
Basic backtest config includes deducting costs (0.0015) for each trade, and we exclude stocks with special treatment (ST), stocks delisted, stocks meeting their limit up/down (making it non-tradable), and newly issued stocks (60 days after listing). Benchmark index is the zz1000 index for computing excess returns.
Portfolio Optimization
With $M$ stocks selected, we would like to know the exact weights of each investment to control the overall risk exposure. Suppose $R \in \mathbb{R}^M$ is the predicted return of the $M$ stocks (machine learning output), $\Sigma \in \mathbb{R}^{M \times M}$ the estimated covariance matrix, and $x \in \mathbb{R}^M$ the weights for each stocks, we have the following constraint optimization problem:
\[\begin{align*} &\max_x \ \ R^T x - \lambda x^T \Sigma x \\ s.t. \ \ &\forall i: \ \ W_{low} \leq x_i \leq W_{high}, \ \ \sum_{i=1}^n x_i = 1 \ \ (\text{Holding Constraint}) \\ &\forall m: \ \ S_{low} \leq (x^T - w_{bench}^T) X_{style_m} \leq S_{high} \ (\text{Style Exposure Constraint}) \\ &\forall k: \ \ I_{low} \leq (x^T - w_{bench}^T) X_{ind_k} \leq I_{high} \ (\text{Industry Exposure Constraint}) \\ &\sum_{i=1}^n |x - x_{t-1}| \leq TO_{limit}\ (\text{Turnover Constraint}) \end{align*}\]The objective function means we would like to maximize returns and minimize risk at the same time. $\lambda = 10$ empirically works the best.
Each constraint comes with a different purpose:
- Holding Constraint: no short-selling, so all weights shall be positive, and we don’t want to over-invest in one stock, so there is also an upper limit for a single stock weight;
- Style Exposure: style factors are also called risk factors, including Market-Cap, Momentum, and others. We would like its exposure to be controlled over time, and not using these factors to obtain excess returns;
- Industry Exposure: prevent over-investing in a single industry. This is the place where an alternative dynamic classification is plugged in.
- Turnover Constraint: limit the rate of replacement of the stocks to lower costs.
Acknowledgement
Special thanks to coworkers and my best friends met at Shanghai Probability Quantitative Investment: Beilei Xu, Zhongyuan Wang, Zhenghang Xie, Cong Chen, Yihao Zhou, Weilin Chen, Yuhan Tao, Wan Zheng, and many others. This project would be impossible without their data, insights, and experiences.
Reference
[1] Gautier Marti, Frank Nielsen, Mikołaj Bińkowski, Philippe Donnat (2020). A review of two decades of correlations, hierarchies, networks and clustering in financial markets. Signals and Communication Technology.
[2] Tumminello, M. and Aste, T. and Di Matteo, T. and Mantegna, R. N. (2005). A tool for filtering information in complex systems. Proceedings of the National Academy of Sciences.
[3] Mel MacMahon, Diego Garlaschelli (2014). Community detection for correlation matrices. Physical Review X.
[4] Won-Min Song,T. Di Matteo,Tomaso Aste (2012). Hierarchical Information Clustering by Means of Topologically Embedded Graphs. PLoS ONE 7(3).
[5] Won-Min Song, T. Di Matteo, Tomaso Aste (2009). Nested hierarchies in planar graphs. Discrete Applied Mathematics.
[6] Amelie Hüttner, Jan-Frederik Mai and Stefano Mineo (2018). Portfolio selection based on graphs: Does it align with Markowitz-optimal portfolios? Dependence Modeling.
[7] V. Plerou, P. Gopikrishnan, B. Rosenow, L. A. N. Amaral, T. Guhr, H. E. Stanley (2001). A Random Matrix Approach to Cross-Correlations in Financial Data. Physical Review E.
[8] R. N. Mantegna (1999), Hierarchical structure in financial markets, The European Physical Journal B-Condensed Matter and Complex Systems 11.
[9] R. N. Mantegna, H. E. Stanley (1999). Introduction to econophysics: correlations and complexity in finance, Cambridge university press.
[10] Aditya Grover, Jure Leskovec (2016). node2vec: Scalable Feature Learning for Networks.
[11] Bijaya Adhikari, Yao Zhang, Naren Ramakrishnan, B. Aditya Prakash (2017). Distributed Representation of Subgraphs.
[12] 石川, 刘洋溢, 连祥斌 (2020). 因子投资方法与实践.
[13] Jianqing Fan, Weichen Wang, Yiqiao Zhong (2016). Robust Covariance Estimation for Approximate Factor Models.
Last Update: 03/08/2022